api/uc.php
在synlogin 函数里面增加如下代码
if(($member = getuserbyuid($uid, 1))) {
dsetcookie('auth', authcode("$member[password]\t$member[uid]", 'ENCODE'), $cookietime);
}else{
// 下面为增加部分
$username = $get['username'];
$password = md5(time().rand(100000, 999999));
$email = $get['email'];
$ip = $_SERVER['REMOTE_ADDR'];
$time = time();
$userdata = array(
'uid' => $uid,
'username' => $username,
'password' => $password,
'email' => $email,
'adminid' => 0,
'groupid' => 10,
'regdate' => $time,
'credits' => 0,
'timeoffset' => 9999
);
DB::insert('common_member', $userdata);
$status_data = array(
'uid' => $uid,
'regip' => $ip,
'lastip' => $ip,
'lastvisit' => $time,
'lastactivity' => $time,
'lastpost' => 0,
'lastsendmail' => 0,
);
DB::insert('common_member_status', $status_data);
DB::insert('common_member_profile', array('uid' => $uid));
DB::insert('common_member_field_forum', array('uid' => $uid));
DB::insert('common_member_field_home', array('uid' => $uid));
DB::insert('common_member_count', array('uid' => $uid));
$query = DB::query("SELECT uid, username, password FROM ".DB::table('common_member')." WHERE uid='$uid'");
if($member = DB::fetch($query)) {
dsetcookie('auth', authcode("$member[password]\t$member[uid]", 'ENCODE'), $cookietime);
}
}
同时修改 source/class/class_member.php
在 on_register 函数里面加 登录的同步函数
uc_user_synlogin($_G['uid'])
如图
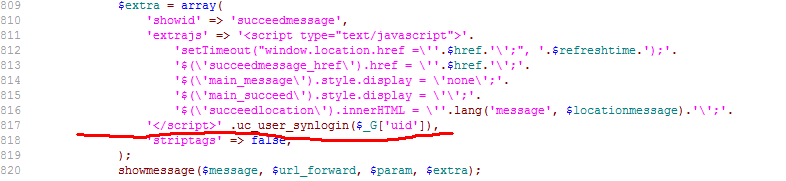
总结一下就是:
在注册函数的成功部分加入 同步请求,同时在那些需要同步的站点改造成自动注册入数据库的功能,从而实现免登陆并且激活
思考: 任何其他程序,都可以考虑完成自己的同步登陆部分,在登陆里面完成uc的用户在本系统的注册问题
比如